Data Driven Testing with Arjuna¶
Purpose¶
Driving an automated test with data is a critical feature in test automation frameworks.
Here, we will explore various flexible options available in Arjuna for data driven testing.
You can supply drive_with argument to the @test decorator to instruct Arjuna to associate a Data Source with a test. Depending on the needs, as described below, you use Arjuna’s markup for different types of data sources.
Single Data Record¶
Sometimes, the need is simple. You have a single data record, but want to separate it from the test code for the sake of clarity.
This need is solved with the record markup of Arjuna. You can provide any number of positional or named arugments.
from arjuna import *
@test(drive_with=record(1, True, a='something', b='anything'))
def check_pos_data(request, data):
pass
We provide drive_with argument to the @test decorator.
To specify a single data record, we call the record factory function.
record can take any number of positional or keyword arguments.
The signature of the test now contains a data argument.
Within the body of the tests, you access the positional values using indices (e.g. data[0])
You can retrieve named values using a dictionary syntax (e.g. data[‘a’]) or dot syntax (e.g. data.a).
Names are case-insensitive. data[‘a’], data[‘A’], data.a and data.A mean the same thing.
You can also use Arjuna’s Arjuna’s generator Construct construct in data record. The generate() call of Arjuna’s generator Construct is optional as data records recognizes when a Arjuna’s generator Construct is supplied as a positional or keyword argument.
from arjuna import *
@test(drive_with=record(generator(Random.first_name).generate()))
def check_generator_with_generate_call(request, data):
pass
@test(drive_with=record(generator(Random.first_name)))
def check_generator_without_generate_call(request, data):
pass
Multiple Data Records¶
You use the records factory function to provide multiple records. It can contain any number of record entries. The test will be repeated as many times as the number of records (2 in this example.)
from arjuna import *
@test(drive_with=
records(
record(1,2,sum=3),
record(4,5,sum=9),
)
)
def check_records(request, data):
pass
The report will contain separate entries for each test. The name will indicate the data used. (e.g. test/pkg/check_04_dd_records.py::check_records[Data-> Indexed:[7, 8] Named:{sum=10}])
Retrieval of data values is done exactly the same way as in case of a single data record.
Driving with Static Data Function¶
Rather than including static data in Python code, one might want to generate data or pull data from an external service to create data records.
A simple way to achieve this is to write a data function. A static data function always behaves in the same manner.
@test(drive_with=data_function(func))
def check_static_data_func(request, data):
pass
We use data_function factory function to associate the data function with the test function Retrieval of values is same as earlier.
Driving with Static Data Generator¶
You can also use a Python generator instead of a normal function:
@test(drive_with=data_function(data_generator))
def check_generator_func(request, data):
pass
Driving with Dynamic Data Function or Generator¶
Another advanced measure that you can take is creating a data function which acts on the arguments supplied by you to govern the data it returns/generates.
from arjuna import *
@test(drive_with=data_function(dynamic_data_func, 8, "something", a="whatever", b=1))
def check_dynamic_data_func(request, data):
pass
Data functions can take any number of arguments - positional as well as named. You supply the arguments in the data_function builder function to control the data function.
Driving with Static Data Classes¶
Instead of a function, you can also represent your data generation logic as a data class. The Data Class must implement Python’s Iteration Protocol. A static data class always behaves in the same manner.
@test(drive_with=data_class(MyDataClass))
def check_data_class(request, data):
pass
We use data_class factory function to associate the data class with the test function. Retrieval of values is same as earlier.
Driving with Dynamic Data Classes¶
Another advanced measure that you can take is creating a data class which acts on the arguments supplied by you to govern the data it generates.
from arjuna import *
@test(drive_with=data_class(MyDataClass, 8, "something", a="whatever", b=1))
def check_dynamic_data_class(request, data):
pass
Data classes can take any number of arguments - positional as well as named. You supply the arguments in the data_class factory function to control the data class.
Driving with Data Files¶
For large, static data it might be useful to externalize the data completely outside of Python code.
Arjuna supports data externalization in XLS, TSV/CSV and INI files out of the box.
You can use data_file factory function to specify a data file. Arjuna determines the loader based on the file extension.
The files are automatically picked up from Data Sources directory which is <Project Root>/data/source.
Driving with Excel File¶
An excel data file (.xls file) can contain data in following format. (.xlsx files are NOT supported as of now)
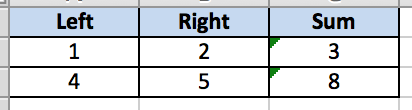
from arjuna import *
@test(drive_with=data_file("input.xls"))
def check_drive_with_excel(request, data):
pass
Driving with Delimited Text File¶
An delimiter-separated data file can contain data in following format.
.txt
Left Right Sum
1 2 3
4 5 8
.csv
Left,Right,Sum
1,2,3
4,5,8
from arjuna import *
@test(drive_with=data_file("input.txt"))
def check_drive_with_tsv(request, data):
pass
@test(drive_with=data_file("input.csv", delimiter=","))
def check_drive_with_csv(request, data):
pass
Default delimiter is tab. If you use any other delimiter, you can pass it as delimiter argument.
Driving with INI File¶
An INI data file can contain data in following format.
[Record 1]
Left = 1
Right = 2
Sum = 3
[Record 2]
Left = 4
Right = 5
Sum = 8
from arjuna import *
@test(drive_with=data_file("input.ini"))
def check_drive_with_ini(request, data):
pass
Data Files with Exclude Filter for Records¶
At times, you might want to selectively mark records in data files to be excluded from consideration.
You can do this by adding a column named exclude and set it to y/yes/true to exclude a record.
For delimiter-separated-files, you can also comment a record by putting a # at the beginning.
For INI files, you can also comment a complete record by using ; which is the commenting symbol for INI files.
Driving with Multiple Data Sources¶
You can associate multiple data sources with a single test in Arjuna.
We can achieve this by using the many_data_sources factory function.
from arjuna import *
@test(drive_with=many_data_sources(
record(left=1, right=2, sum=3),
records(
record(left=3, right=4, sum=7),
record(left=7, right=8, sum=10)
),
data_function(myrange),
data_class(MyDataClass),
data_file("input.xls")
))
def check_drive_with_many_sources(request, data):
pass
The data sources are picked up sequentially with this construct.