Data References¶
Purpose¶
Data References represent global data containers which can be accessed from anywhere in your test project.
Arjuna supports two types of data references - Contextual and Indexed - as discussed below. For each of them Excel and YAML formats are supported.
These reference files are automatically loaded when Arjuna.init() is called by Arjuna launcher.
Contextual Data References¶
There are various situations in which you need contextual data. Such a need is catered by the concept of Contextual Data References in Arjuna.
Consider the following example: 1. You have 3 types of user accounts - Bronze, Silver and Gold. 2. The user account information includes a User and Pwd to repesented user name and password representing a given account type. 3. In different situations, you want to use the user accounts and retrieve them by the context name from a single source of information.
You place such files in <Project Root>/data/reference/contextual directory.
Excel based Contextual Data References¶
A reference file can be found arjex project.

The context of data is represented by columns. Here Account Type’s values - Bronze, Silver and Gold represent the contexts, for which the User and Pwd values are different.
YAML based Contextual Data References¶
For more complex data needs, YAML could be a better format than Excel, with the benefit that you can track changes in a source control system.
A reference file can be found arjex project.
Following is a sample of the same data as represented in Excel in previous section:
Bronze: User: B1 Pwd: BP1 Silver: User: S1 Pwd: SP1 Gold: User: G1 Pwd: GP1
The context of data is represented by keys/section names in the root of YAML. Here Account Type’s values - Bronze, Silver and Gold represent the contexts, for which the User and Pwd values are different.
The Magic R Function for Contextual References¶
You can access contextual data references in your test code with Arjuna’s magic R function (similar to L and C functions seen in other features).
It has the following signature. The first argument is the query. bucket and context are optional arguments, if query includes them.
R("user", bucket=<bucket_name>, context=<context_name>))
The name of the file is the bucket name (without the extension).
- You can retrieve values from contextual data reference with a combination of bucket, context and reference name.
Query can be of format bucket.context.refname without passing bucket and context arguments separately.
bucket.context.refname # For example R("eusers.bronze.pwd")
- Query can be of format context.refname and bucket can be supplied as argument.
context.refname # For example R("bronze.pwd", bucket="eusers")
- Query can contain just the reference name and bucket and context arguments can be provided.
refname # For example R("pwd", bucket="eusers", context="bronze")
Indexed Data References¶
There are situations where the data reference is a list/sequence of objects which you want to access by their position rather than against a name/key.
This global data need is met with Arjuna’s Indexed Data References.
Consider the following example: 1. You have a list of eCommerce site coupons. 2. Sometimes you want to use them all, sometimes you want to choose one at random and so on. 3. They share the same context. There is no special meaning to one item differentiating itself from another. In simple words, all are equivalent.
You place such files in <Project Root>/data/reference/indexed directory.
Excel based Indexed Data References¶
A reference file can be found arjex project.
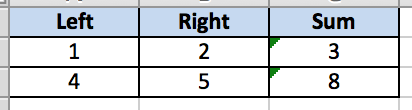
Each row is mapped to the heading strings in the first row. Indexing starts at 0 and from the first data row.
YAML based Contextual Data References¶
A reference file can be found arjex project.
Following is a sample of the same data as represented in Excel in previous section:
- Left: 1 Right: 2 Sum: 3 - Left: 4 Right: 5 Sum: 8
The Magic R Function for Indexed References¶
You can access indexed data references just like contextual ones in your test code with Arjuna’s magic R function.
It has the following signature. The first argument is the query. bucket and index are optional arguments, if query includes them.
R("user", bucket=<bucket_name>, index=<index>))
The name of the file is the bucket name (without the extension).
- You can retrieve values from indexed data reference with a combination of bucket, context and reference name.
Query can be of format bucket.index.refname without passing bucket and context arguments separately.
bucket.index.refname # For example R("eusers.1.pwd")
- Query can be of format index.refname and bucket can be supplied as argument.
1.refname # For example R("1.pwd", bucket="eusers")
- Query can contain just the reference name and bucket and context arguments can be provided.
refname # For example R("pwd", bucket="eusers", index=1)
Retrieving Complete Referred Object¶
In the above sections we saw retrieving a name/key in the referred object by context or index.
You can also retrieve the complete object in one shot.
Get Contextual Data Reference Object¶
- You can retrieve the object from contextual data reference with a combination of bucket and context.
Query can be of format bucket.context without passing bucket and context arguments separately.
bucket.context # For example R("eusers.bronze")
- Query can be of format context and bucket can be supplied as argument.
context # For example R("bronze", bucket="eusers")
- Query can be blank if bucket=”eusers” and context=”bronze” are passed arguments to R()
R(bucket="eusers", context="bronze")
Get Indexed Data Reference Object¶
- You can retrieve object from indexed data reference with a combination of bucket and index.
Query can be of format bucket.index without passing bucket and index arguments separately.
bucket.index # For example R("eusers.1")
- Query can be of format index and bucket can be supplied as argument.
index # For example R("1", bucket="eusers")
- Query can be blank if bucket=”eusers” and index=1 are passed arguments to R()
R(bucket="eusers", index=1)
Retrieving Complete Contextual/Indexed Data Reference¶
In the above sections we saw retrieving a name/key in the referred object by context or index.
You can also retrieve the complete Data Reference.
Using R() and Query¶
R(bucket_name) # For example R("eusers") R(bucket=bucket_name) #For Example R(bucket="eusers")
Using Arjuna.get_data_ref()¶
As for this use case the query is not of much use, an easier way is to do the following:
Arjuna.get_data_ref(bucket_name)
Contextual Data References Behave Like Python Dicts¶
If you retrieve the a contextual data reference, you can treat it like a Python dict:
data_ref[context_key] data_ref.keys() data_ref.items() for context in data_ref: # do something for context, record in data_ref.items(): # do something
Indexed Data References Behave Like Python Tuples (Sequences)¶
If you retrieve the an indexed data reference, you can treat it like a Python tuple (sequence):
data_ref[index] for record in data_ref: # do something