Data Localisation¶
Purpose¶
As a part of automating tests, a test author might need to deal with localization of strings that are used for various purposes.
Arjuna supports Excel based localization data out of the box. These files are automatically loaded when Arjuna.init() is called by Arjuna launcher.
Locale Enum¶
Arjuna associates locale for localization with the Locale enum constant which in turn uses the names from Python.
The default locate is Locale.EN. It can be changed in a project configuration as follows:
# project.yaml
arjuna_options:
l10n.locale: hi
Excel based Localization¶
Sample Localization File¶
The localization file follows the format of Excel Column Data Reference files.
You place such files in <Project Root>/l10n/excel directory. Two reference files can be found in this example project.
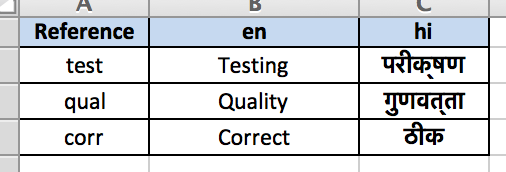
First column is always the Reference column. The other columns represent the languages mentioned as Locale type in column heading.
In the example file, the columns mentions en and hi which are Locale value for English and Hindi respectively.
For demonstration purpose, 3 English words are provided with corresponding strings in Hindi.
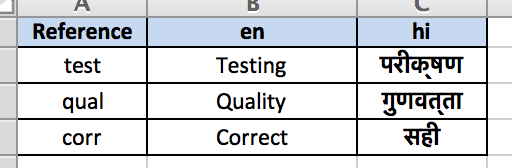
The second file sample2.xls has the same data except the localized string for Correct in Hindi which is different from sample1.xls.
The L function for Localization¶
You can access data references in your test code with Arjuna’s magic L function (similar to C and R functions seen in other features).
It has the following signature. The first argument is the query. locale, bucket and strict are optional arguments.
L("qual", locale=<local enum constant or string>, bucket=<bucket_name>, strict=<True or False>)
L(“Testing”) localizes the string as per the ArjunaOption.L10_LOCALE value in reference configuration. In project.yaml, we have set it as HI.
You can also explcitily mention the locale as Locale.HI.
When a name is repeated across multiple localization files (buckets), the last one holds. L(“Correct”) will give the value from sample2 file as it is loaded after sample1.
You can explcitily refer to a bucket by providing the bucket argument. Each Excel localization file represents a bucket and its name without the extension is the bucket name.
You can also provide the bucket name by prefixing it before the reference key, for example sample1.corr.
strict argument is to switch strict node on or off.
JSON Based Localization¶
Sample Localization Files¶
With JSON format, there is a specific structure expected. The sample files are placed in <Project Root>/l10n/json directory.
Following is the sample JSON localization structure:
json
├── bucket1
│ ├── de-DE.json
│ └── en-GB.json
├── bucket2
│ ├── de-DE.json
│ └── en-GB.json
├── de-DE.json
└── en-GB.json
Each directory represents a bucket with the name as that of directory. The concept is similar to an Excel file representing a bucket as discussed above.
The root directory represents the root bucket.
For a given bucket, the localization data for a Locale is kept in a file named <locale>.json.
Sample JSON Content¶
Following is the content of one such file in root directory for German localization:
{
"address": {
"address": "Adresse",
"city": "Stadt",
"coordinates": "Koordinaten",
"country": "Land",
"houseNumber": "Hausnummer",
"latitude": "Breitengrad",
"location": "Ort",
"longitude": "Längengrad",
"postalCode": "Postleitzahl",
"streetName": "Straße"
},
"shared": {
"back": "zurück",
"cancel": "Abbrechen"
}
}
Each JSON path of keys repesents a string to be localized.
The key names should be kept same across language files.
Key1.Key2…KeyN is the flattened syntax to refer a localized string e.g. address.coordinates
Using the L Function with JSON Localizer¶
Consider the following localization calls:
L("error.data.lastTransfer", locale=Locale.EN_GB) # From global l10n container
L("error.data.lastTransfer", locale=Locale.DE_DE) # From global l10n container
L("error.data.lastTransfer", locale=Locale.EN_GB, bucket="bucket2") # From bucket2
L("bucket2.error.data.lastTransfer", locale=Locale.EN_GB) # From bucket2
L("address.coordinates", locale=Locale.EN_GB, bucket="bucket2")
L("address.coordinates", locale=Locale.EN_GB, bucket="root")
L("root.address.coordinates", locale=Locale.EN_GB)
Use the flattened key syntax as discussed earlier.
The key names should be kept same across language files.
Key1.Key2…KeyN is the flattened syntax to refer a localized string e.g. address.coordinates
Files in root localization directory are available in root bucket.
Strict vs Non-strict Mode for Localization¶
By default, Arjuna handles localization in a non-strict mode. This means if localized string is absent for a given reference, it ignores the error and returns the reference as return value.
L("non_existing")
L("non_existing", strict=True, locale=Locale.DE_DE)
As by default the strict mode if off, L(“non_existing”) returns non_existing.
You can enforce strict behavior by providing the strict=True argument to the L function. The second print statement in above code will raise an exception.
You can switch on strict mode at the project level by including l10n.strict = True in the project.yaml file.